Ten Reasons Why You Need DataStage 8.5
taken a look through the new
functions and capabilities of DataStage 8.5 and come up with a top ten list of
why you should upgrade to it.
Information Server 8.5 came out a
couple weeks ago and is currently available on IBM Passport Advantage for existing customers and
from IBM PartnerWorld for IM partners. The XML pack described below is
available as a separate download from the IBM Fix Central website.
This is a list of the ten best
things in DataStage 8.5. Most of these are
improvements in DataStage Parallel Jobs only while a couple of them will help
Server Job customers as well.
1.
It’s Faster
Faster, faster, faster. A lot
of tasks in DataStage 8.5 are at least 40% faster than 8.1 such as starting
DataStage, opening a job, running a Parallel job and runtime performance have
all improved.
2.
It' is now an XML ETL Tool
Previous versions of DataStage were
mediocre at processing XML. DataStage 8.5 is a great XML processing
tool. It can open, understand and store XML schema files. I did a
longer post about just this pack in New Hierarchical Transformer makes DataStage great a XMLTool and if you have XML files without schemas you can follow a tip
at the DataStage Real Time blog: The new XMLPack in 8.5….generating xsd’s….
The new XML read and transform
stages are much better at reading large and complex XML files and processing
them in parallel:

3.
Transformer Looping
The best Transformer yet. The
DataStage 8.5 parallel transformer is the best version yet thanks to new
functions for looping inside a transformer and performing transformations
across a grouping of records.
With looping inside a Transformer
you can output multiple rows for each input row. In this example a record
has a company name and four revenue sales figures for four regions – the loop
will go through each column and output a row for each value if it is populated:

4. Transformer Remembering
DataStage 8.5 Transformer has
Remembering and key change detection which is something that ETL experts have
been manually coding into DataStage for years using some well known
workarounds. A key change in a DataStage job involves a group of records
with a shared key where you want to process that group as a type of array
inside the overall recordset.
I am going to make a longer post
about that later but there are two new cache objects inside a Transformer –
SaveInputRecord() and GetSavedInputRecord(0 where you can save a record and
retrieve it later on to compare two or more records inside a Transformer.
There are new system variables for
looping and key change detection - @ITERATION, LastRow() indicates the last row
in a job, LastTwoInGroup(InputColumn) indicates a particular column value will
change in the next record.

Here is an aggregation example where
rows are looped through and an aggregate row is written out when the key
changes:
4.
Easy to Install
Easier to install and more
robust. DataStage 8.5 has the best installer of any version of DataStage
ever. Mind you – I jumped aboard the DataStage train in version 3.6 so I
cannot vouch for earlier installers but 8.5 has the best wizard, the best
pre-requisite checking and the best recovery. It also has the IBM Support Assistant packs for Information
Server that make debugging and reporting of PMRs to IBM much easier.
There is also a Guide to Migrating to InfoSphere Information Serve 8.5 that
explains how to migrate from most earlier versions.
See my earlier blog post Why Information Server 8.5 is Easier to Install thanInformation Server 8.1.
Patch Merge – that’s right, patch
merge. The new installer has the ability to merge patches and fixes into the
install for easier management of patches and fixes.
5.
Check In and Check Out Jobs
Check in and Check out version
control. DataStage 8.5 Manager comes with direct access to the source
control functions of CVS and Rational ClearCase in an Eclipse workspace.
You can send artefacts to the source control system and replace a DataStage
component from out of the source control system.

DataStage 8.5 comes with out of the
box menu integration with CVS and Rational ClearCase but for other source
control systems you need to use the Eclipse source control plugins.
6.
High Availability Easier than ever
High Availability – the version 8.5
installation guide has over thirty pages on Information Server topologies
including a bunch of high availability scenarios across all tiers of the
product. On top of that there are new chapters for the high availability
of the metadata repository, the services layer and the DataStage engine.
- Horizontal and vertical scaling and load balancing.
- Cluster support for WebSphere Application Server.
- Cluster support for XMETA repository: DB2 HADR/Cluster or Oracle RAC.
- Improved failover support on the engine.
7. New Information Architecture
Diagramming Tool
InfoSphere Blueprint Direct –
DataStage 8.5 comes with a free new product for creating diagrams of an
information architecture and linking elements in the diagram directly into
DataStage jobs and Metadata Workbench metadata. Solution Architects can
draw a diagram of a data integration solution including sources,
Warehouses and repositories.

8. Vertical Pivot
There are people out there who have
been campaigning for vertical pivot for a long time – you know who you
are! It is now available and it can pivot multiple input rows with a
common key into output rows with multiple columns. Key based groups,
columnar pivot and aggregate functions.
You can also do this type of
vertical pivoting in the new Transformer using the column change detection and
row cache – but the Vertical pivot stage makes it easier as a specialised
stage.
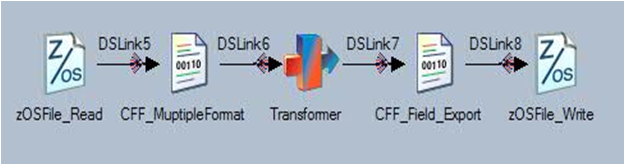
9. Z/OS File Stage
Makes it easier to process complex
flat files by providing native support for mainframe files. Use it for
VSAM files – KSDS, ESDS, RRDS. Sequential QSAM, BDAM, BSAM. Fixed
and variable length records. Single or multiple record type files.
10. Balanced Optimizer Comes
Home
In DataStage 8.5 the Balanced
Optimizer has been merged into the Designer and it has a number of usability
improvements that turns DataStage into a better ETLT or ELT option.
Balanced Optimizer looks at a normal DataStage job and comes up with a version
that pushes some of the steps down onto a source or target database
engine. IE it balances the load across the ETL engine and the database
engines.
Version 8.5 has improved logging,
improved impact analysis support and easier management of optimised versions of
jobs in terms of creating, deleting, renaming, moving, compiling and deploying
them.

No comments:
Post a Comment